Science
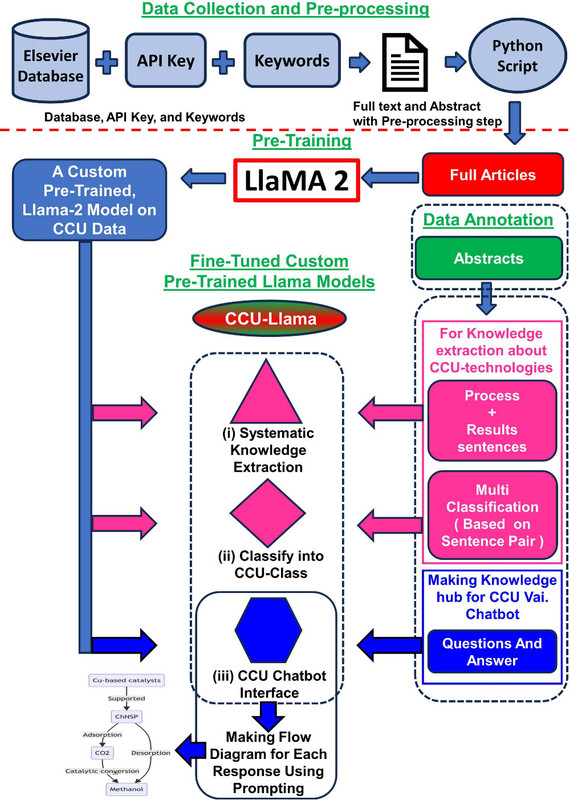
Related: About this forumCCU-Llama.
Ya' gotta love abbreviations.
(I'm having a hard time as an old man with the obsolescence of something called "words." )
The paper in question that stimulated this remark about the (annoying?) abbreviations is this one: CCU-Llama: A Knowledge Extraction LLM for Carbon Capture and Utilization by Mining Scientific Literature Data Harshitha Chandra Jami, Pushp Raj Singh, Avan Kumar, Bhavik R. Bakshi, Manojkumar Ramteke, and Hariprasad Kodamana Industrial & Engineering Chemistry Research 2024 63 (41), 17585-17598
"CCU" is an abbreviation with which I am very familiar, making it almost a word, "carbon capture and utilization," as opposed to "CCS" "carbon capture and storage," the latter being, like hydrogen, a scam designed to greenwash dangerous fossil fuels.
Anyway, I like what the paper's about, which is data mining to find and flow chart processes designed to fix carbon from carbon dioxide in useful products; we may debate which are sustainable products and which are not. (Hint: Plastics and carbon fibers designed for long term use are more sustainable than single use plastics, for one example.)
Text from the paper's introduction:
Various researchers have contributed to developing efficient technologies for capturing carbon content from gaseous effluents from industries and other resources. Currently, industries are adopting these approaches rapidly to neutralize their carbon footprints in their processes. These include chemical and physical methodologies used for capturing CO2, such as absorption, adsorption, membrane separation, cryogenic separation, and chemical looping. Generally, absorption involves the use of liquid solvents to capture gaseous compounds. Aron and Tsouris (6) have utilized monoethanolamine (MEA) as a solvent to capture CO2 from flue gas streams. Similarly, the amine-based scrubbing approach is discussed by Wang et al. (7) and Rajendran et al. (8) Sorbent-based technologies can potentially reduce the overall cost associated with carbon capture significantly. (9) In the adsorption process, solid adsorbents such as silica, zeolites, alumina, metal oxides, activated carbon, and metal–organic frameworks (MOFs) were reported to capture CO2 from gas streams. (10−12) Membrane separation involves the use of selective membranes to separate CO2 from gas mixtures and has been studied by Wu et al. (13) and Pfister et al. (14) Cryogenic separation utilizes low temperatures to condense CO2 from the gas streams. This approach is reviewed extensively by Cann and Udemu. (15) Chemical looping combustion is a combustion process that involves the use of metal oxide particles as oxygen carriers. This method is proposed by Lyngfelt et al. (16) These methods represent diverse approaches for capturing CO2 from the emission stream, each with its advantages and challenges. The captured carbon dioxide is compressed and employed in various applications, including gas and oil recovery, agriculture, soda ash manufacturing, and the food industry. (17,18) Additionally, it can be utilized to produce value-added chemicals and fuels. Alternatively, the captured carbon dioxide can be stored in geological reservoirs or saline aquifers. (19−23) As there are several research works done in this area, it may be beneficial that some of this information can be summarized and/or presented in a useful manner.
Natural language processing (NLP) is a subset of artificial intelligence (AI), primarily focusing on inferring from textual datasets. These datasets, often termed nonstructural, pose a challenge for traditional machine learning or deep learning algorithms. Hence, NLP tools are indispensable for processing them effectively. The increasing accessibility of computational power and resources has further incentivized the utilization of available textual datasets. (24) In early 2000, neural language modeling was developed, in which the probability of the occurrence of the next word (token) is determined by previous work of Bengio et al. (25) Mikolov et al. proposed a word embedding process addressing the dense vector representation of text. (26)...
There you have it folks, "natural language processing" is "NLP." Don't forget it. It saves typing.
With reference to the "increasing accessibility of computational power," it's been in the news that these data centers have high demand for continuous uninterrupted power, of which there are two types, one being dangerous fossil fuel combustion, and the other being clean and sustainable nuclear power. As the big computational companies are making noise about going "green," this has stimulated interest in new nuclear power; and in some cases, as with the proposed restart of a Three Mile Island reactor, previously mothballed nuclear plants.
Nuclear powered data centers are definitely appealing, particularly in cases like this, where the computational power is being directed at addressing an intractable problem, the extreme global heating we are now experiencing.
Some figures from the text:
The caption:
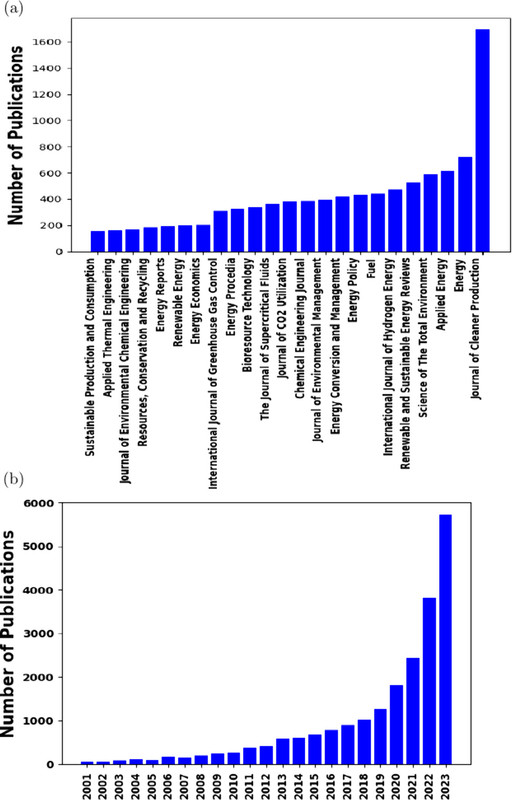
The caption:
I do find myself in some of these journals from time to time, but in general, with the possible exception of their wonderful journals relating to nuclear power, I'm not an Elsevier kind of guy. The point of this paper though is to help one search through the journals one doesn't read regularly to find what it is useful. It's Google Scholar on steroids, generally.
Recently I had to give a scientific talk, and I asked an assistant, a young woman born into and well equipped for the computer age - as opposed to a dinosaur such as myself - to produce a chatGPT version of what I planned to say. I'm very happy to report that I'm still pleased to be a human being. The version she gave me needed lots of work - maybe a sentence or two in the talk I gave was retained.
Sigh...
Anyway, figures relating to the difference between "CCU-Llama" vs. "ChatGPT" appears in the next two figures:

The caption:
Another:
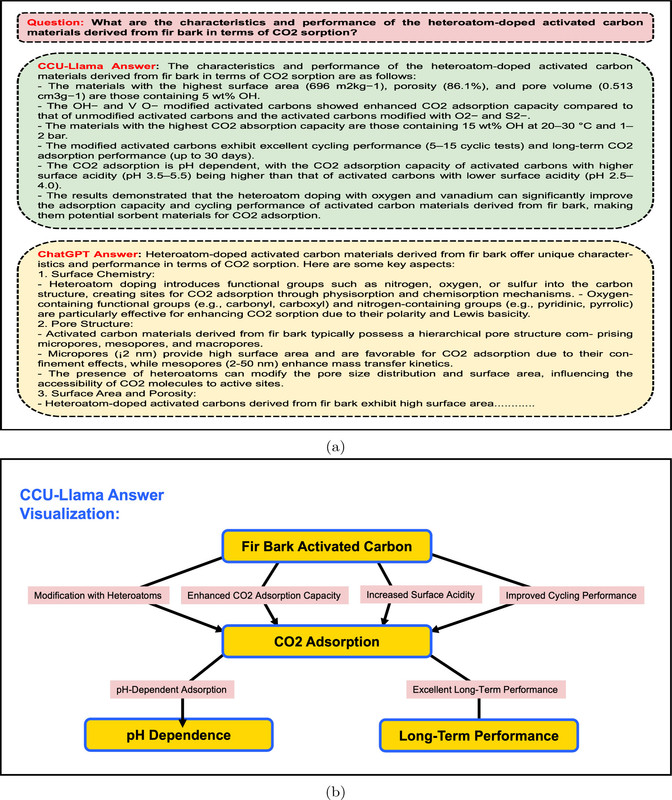
The caption:
Some of the paper's conclusions:
OK then...
Cool, or hot, I guess...
Have a pleasant Sunday.
 = new reply since forum marked as read
Highlight:
NoneDon't highlight anything
5 newestHighlight 5 most recent replies
= new reply since forum marked as read
Highlight:
NoneDon't highlight anything
5 newestHighlight 5 most recent replies

NNadir
(37,064 posts)...take me many hours and lots of work to make a list of the best absorbents in my files, with the understanding that there may be thousands of papers that I never accessed with even better absorbents.
(I was inspired to do this because I came across an adsorbent that can capture uranium from very dilute sources to make a composition richer than the best uranium ores.)
As the end of my life approaches, it seems that we are entering an age of new computational tools that can sort through our vast knowledge to identify the best knowledge, and the paper I linked in this obscure post, came back to me.
So I reached out to my son to see if kids today in Graduate school are using these kinds of data mining tools to benchmark their work.
They should you know...
This post is a little note to myself.
I'll take it up with him when we talk.